
Artificial Intelligence has long been the preserve of science fiction. However towards the end of last year I was asked to do my usual trends lecture on the upcoming 12 months. It struck me during this preperation that for the first time I could see the possible emergence of A.I. capability in the very near future. This is not because recent advances with personal digital assistance such as Apple’s Siri or the fact that Facebook has started using pretty innovative algorithms to exert learning from its social network community or even the number of acquisitions we are seeing amongst silicon valley’s elite. To understand why I have arrived at such a conclusion we need to step back and answer a few fundamentals. Moveover we need to examine the evolution of computing and how it can be leveraged to bring intelligence to its current mere data processing role.
Lets begin this journey.
216 years ago Michael Faraday started to understand the properties of the electron and in particular the effects of electromagnetism. 1897 Sir Joseph John Thomson first proved the concept of the electron being a particle. Probably the most defining moment that enabled the birth place of modern electronics and computing. Without the properties of the electron and how electromagnetism is conveyed by these fundamentals of quantum mechanics we could not possibly even begin to develop computers that are able to manipulate electronics in such as way as to develop out a stored programme. Of course Charles Babbage proved our ability to mechanically create a stored computer programme through his invention of the Difference Machine in 1822, however without JJ Thomson’s discovery Charles Babbage would have been left fashioning new gears for his machine at a faster rate than the Saturn V burns rocket fuel, if it were to stand any chance of computing the simplest of spreadsheet formulas. Clearly the electron was the only way to go. It was then over to the likes of Alan Turing, John Bardeen, Walter Brittain and William Shockley, to name but a few of the great men, to continue the journey of electron and electromagnetic manipulation to evolve into today’s computer.
This allowed us to get this far, which I will pick up later in this article, however if we are to even begin to understand how we could possibly turn today’s modern computer into anything near intelligent we must first answer a few basic questions and ponder a few basic thoughts?
So first and foremost how do we define intelligence?
There, indeed, maybe many ways to answer this simple question including one’s capacity for logic, abstract thought, understanding, self-awareness, communication, learning, emotional knowledge, memory, planning, creativity and problem solving. Alone this seems like an impossible list for today’s computing to grapple with. But focusing on the key words of logic, communication, memory, planning, problem solving all are great traits of today’s modern computer. So we may have something to work with after all. Moreover another view is the ability to perceive information and retain it as knowledge to be applied towards adaptive behaviour within an environment. In essence the ability for the machine to learn from its environment therefore gaining knowledge and perception.
Lets pause on this for a second, if we can perceive information, learn from an environment, extract knowledge, problem solve, communicate, process logic, then there are untold applications for today’s digital world. Consider big data alone and what this means to our understanding when processing large amounts of visits and or transactions on the average digital estate of the average bluechip. This is big! This is very big for our world?
But how do computers compete with humans?
Take our brains which are twice as large as our nearest intelligent competitor i.e. the Bottlenose Dolphin. Three times as large as a Chimpanzee. Our brains are arguable the most complex single object in the known universe. 85 billion neurone cells plus another 85 billion other cell types. Each neurone are electronically excitable cells with between 10, 000 to 100,000 connections creating neurone networks that train the flow of electrons to encode our memory and intelligence. In essence the training and building of these networks forms our software.
85 00 000 000 000 000 neuron connections
vs
4 00 000 000 000 stars in our galaxy
Pretty complex to say the least.
You could argue nature 1 vs Electronics 0
However consider today’s most powerful microprocessors on average we are looking at
100 000 000 000 transistors (switches)
vs
85 00 000 000 000 000 human neurone connections.
But obviously a switch cannot compete with a neurone and its connections each of which is comparable to a software programme in its own right, however when you factor timescales.
Nature 30 billion years
vs
Electronics 216 years
You could argue it’s more than achievable and is just a case of when rather than if.
After all each modern computer is just a bunch of circuits operating at high speed.
Back to Basics
Lets see the fundamentals of how these circuits give us our computing capability and how we can role this forward to create intelligence.

Figure 1.0 – basic electronic circuit.
Everyone surely should remember elementary science experiments to build the basic circuit with a battery, light and switch. Using this concept I want to illustrate how we build up today’s computer and how this logic goes further to develop out what’s equivalent to those neurones and connections that we outlined in our battle with nature.

Figure 1.1 – How the circuit can be configured into a simple logic gate for an OR
Developing the circuit by organising switches and wiring enables us to build basic logic gates. Logic gates form the basic building block in our computing programmes and computer memory. For those of you that are nor familiar with electronics or computer science its worth spending a few minutes tracing out what the electricity is doing here and how the configuration of circuit can truly enable some rudimentary logic.

Figure 1.2 – How the circuit can be configured into a simple logic gate for an AND
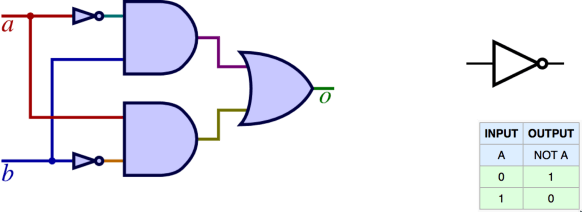
Figure 1.3 – How the circuit can be configure to make a NOT logic gate ( note i’ve moved from standard circuit notation to the symbols in order to make it easier to read, the wires quite quickly get messy)
Whilst there are many types of gates, these three basic ones give us the capability to create computer memory to handle 1 bit of data. i.e. we can store data of a zero or 1 value in our circuit as long as there is power applied to it. These gates are OR, AND, NOT. If you have time its worth working through the logic here. It does work!!! If you don’t trust me this gate will hold a value of 0 or 1 indefinitely as long as it receives power.
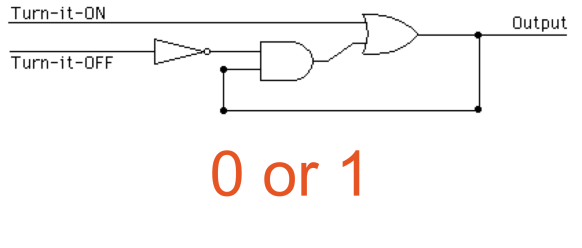
Figure 1.4 – 1 bit memory circuit configured from NOT AND OR gates
Once we can handle 1 bit of memory we can scale the electronics up to handle 1 bit to 32 to 64 bits. We can then scale this out to use our bits to form bytes of memory. i.e. a collections of bits to make a byte, which in turn gives our byte of memory, which in turn we add many bytes to. Roughly a byte can handle a character through ASCII representation. ASCII is a basic binary encode method for characters. The ascii code for the letter A in binary is 01100001. This takes 8 bits or equivalent to 8 memory circuits outlined figure 1.4.
So we now can store this information. However imagine how many circuits would need to be wired to implement one byte of memory. You can appreciate the wires and switches that would be needed to make this work. Hence the need to scale the circuit down to a miniature format The first stop on this journey is the transistor, which for me is the most remarkable achievement of the modern electronics age. The manipulation of quantum electrodynamics(QED) enables us to miniaturise this simple switch through the use of semiconductor material. This was then further miniaturised into microprocessors.
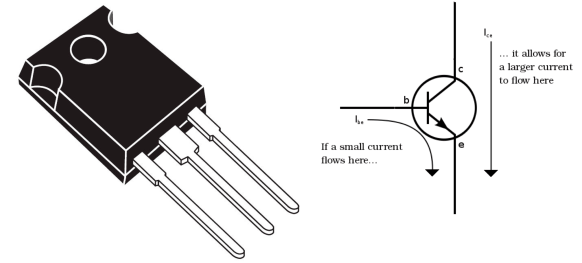
Figure 1.5 – The transistor and the beginning of miniaturisation

Figure 1.6 – Microprocessor magnified showing numerous transistors
But how do we build our computer. To start we need to focus back on our memory. The thing with memory is it allows us to remember, it can remember a value, it can remember an instruction and it can remember an address of a memory location. Each bit i.e. 0 or 1 can be wired back into our computer to allow each value to be fetched and transferred back through the central processing unit for processing.
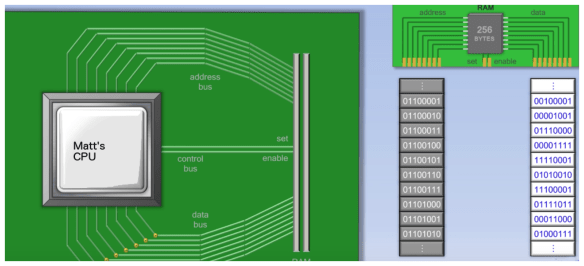
Figure 1.7 – shows our memory broken down into bits i.e. the 0 and 1 which in turn are made into bytes. i.e. 01100001. The memory consist of 256 bytes, in this instance, with memory address location identity in grey with its associated value shown in white. Each bit is physically wired into the cpu via one cable, this is called the bus. There are two types of bus, one is the data bus and one is the address bus. We also have a control bus which is a simple 2 bit “set and enable” bus(set stores and value, enable retrieves a value). The way the memory works is to set a value in a particular address location. For example if address location is 01100001 (i.e. top of the grey location) in the address bus by applying electric current down the wires with the following configuration, 00100001, then this is sent down the data wires when the control bus is set to 1 i.e. the 00100001 will then be stored in the circuit wiring for that particular byte of memory and that particular address location.
In short we have a mechanism to set and enable data values linked to an address in memory. Each memory circuit is made up of logic gates outlined in 1.4. We can then fetch and set data in those logic gates. This means we can both store information for calculation and store information for instructions. Two of the most important components of a computer programme.
We can now deal with fetching data and storing data in main memory. Now we need to lift the lid on the CPU to see what’s going on underneath.

Figure 1.8 outlines my basic CPU design. You can see from this diagram our wiring from the address buses, data buses and control buses. These link out to the right of the diagram back to our main memory outlined in figure 1.7. Inside the CPU you can see many components;-
- CPU Clock
- Control Unit
- Arithmetic Logic Unit ALU
- A bunch of registers
Arguably the most important component of this architecture is the CPU clock, this is the thing that identifies a processors speed, for example 200 ghz (200 billion times per second). Again like the memory circuit, the clock is made up of logic gates configured in a way to control a pulse of activity around all the circuits. When the clock says go, the circuits switch and move to process the next instruction. Ultimately all the CPU needs to do is to fetch and execute an instruction. This through no coincidence is called the fetch execute cycle. Figure 1.9 outlines how memory is just made up of instructions each one makes up our programming language. If we can process through this list we can process a programme.
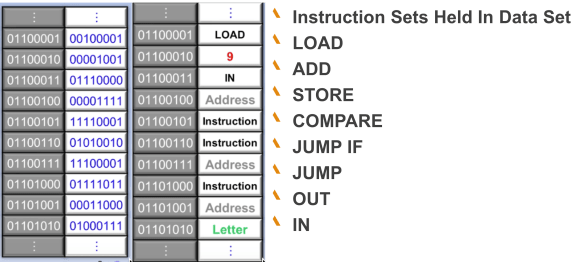
Figure 1.9
The next component of our CPU is the Control Unit again a bunch of logic gates. The control unit works with the clock to coordinate activity within the CPU. Its intrinsically linked to a bunch of registers, these registers store data in exactly the same way as memory, but much closer to the CPU. They are there to store things like the address for the next instruction, the value of the instruction just processed, the address of the memory location to store the result, the values of the two sums to be added together. The control unit processes what the instruction is. i.e. Load, Add. Store. It then uses the registers to store the locations of where the data is to be fetched from stored to etc etc.
The final component of our CPU is the Arithmetic logic unit. This is what does the computation. In its simplest form it is giant calculator made up of logic gates.
So in order for us to work our CPU needs a programme. This could be as followings;-
Address Location = Data value in binary
01100011 = LOAD (10101101)
01100101 = Address(10011011)
10011011 = 9(00001001)
10011010 = ADD (10111011)
01100011 = LOAD (10101101)
10010111 = Address(10011111)
10011111 = 6 (00000110)
The CPU will fetch the first line with an instruction to LOAD. Load means nothing other than the binary value 10101101, its an arbitrary instruction that means that the control unit in the CPU will go and load the next instruction in memory into the register. This instruction happens to be the address of the next value. i.e. 01100101 = Address(10011011). Which in turns goes to memory location 10011011 = 9(00001001) and gets the value 9. It then goes on to get the ADD operation which in turn then goes to get the value 6. The programme is basically asking us to add 9 to 6.
You get the picture, the control unit is manipulating the registers, memory and ALU to process the programme in memory. Using the buses to transfer data using the addresses and using the control buses to set or enable values from memory and registers. All of which is synchronised and controlled by the CPU clock. The concept is simple but the speed is the thing that makes us have the ability to processes billions of instructions per second, hence the many wonderful things you can do with today’s computers from spreadsheets to augmented reality. As a side note the binary numbers are our machine code. In order to make it easier for programmers, instructions are encoded through an interpreter this enables us to create an assembly language i.e. Load, address, add etc, etc,. Each microprocessor as to interpreted from assembly to its own machine code instruction. Assembly language in turn can be extrapolated further into higher level programming language such as C++, Java or others where we have compilers interpreting our language and mapping it to the processor specifics. Compilers allow us to write one set of code that then can be interpreted to many different CPU architecture types.
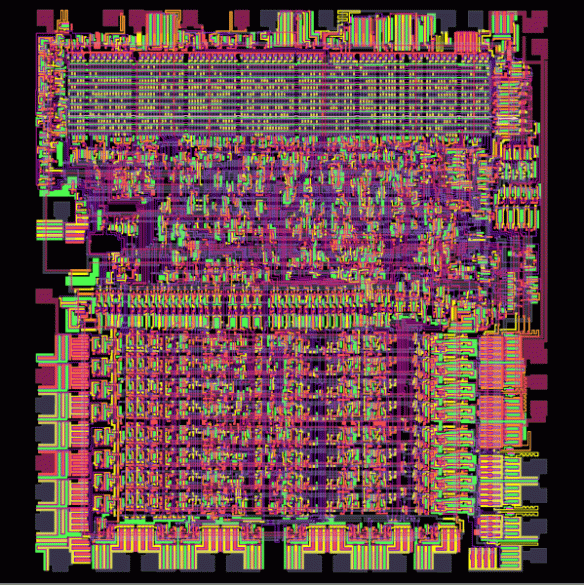
Figure 2.0 – MOSS 6502 CPU up close and personal. This is the micro processor that powered the famous Apple II computer. The top right of the diagram shows the CPU clock. The big block at the bottom shows the control unit and registers, the bit in the middle / near top show the ALU. The buses are the neat grid lines where the logic gates made up of many layers of mini transistors appear rather messy in design.
So we’ve built a CPU. Lets make it smart
Any Computer scientist knows the basics of the above. The challenge is to make this intelligent. How do we do this and what do we have;-
- Speed to execute and process billions of instructions per second.
- The ability to apply logic i.e. encoding rules and knowledge
- Ability to re programme ourselves
- Ability to process instructions in a parallel way i.e. today’s modern processes have many core i.e. many CPUs that can run in parallel.
- Ability to remember on a large scale.
So in essence we have the building blocks of intelligence we just need the programmes to make it work. It’s all about the software engineering! But with software engineering there are many forms of architecture approach to implement a programme that could deliver intelligence. A.I. can be considered as have the following schools;-
- Knowledge Representation
- Planning
- Natural Language Processing
- Machine Perception
- Motion and Manipulation
- Long term goals
- Neural Networks
Each branch of A.I. is exciting in its own right, however for me the area which is closest to mimicking the way our brains work is that of Neural Networks which have been around for sometime. To be precise they were initially pioneered as mathematical networks based on algorithms using threshold logic. This was as early as 1943 and was obviously not computational in the modern sense of the word but purely linked to mathematical models to represent inputs, calculations and outputs which in turn are fed into new inputs. Our brains don’t understand the concept of mathematical notation when we go down to the level of how neurones process electrical signals through the 100s of thousands of connections they develop. However each connection links to more connections forming a network. This is our software but a software that is able to reprogramme itself constantly based on calculations, output and environmental inputs. So in order to build A.I. software we must encapsulate the following capability;-
- Encode rules in a programme
- Enable that programme to take input in the form of data and the output of previous calculations
- The ability for that programme to score the success of the result of its calculation
- The ability for the programme to rewrite itself i.e. encode the rules again to optimise the result.
In short, input, calculate, output, learn, reprogramme. As a developer, to even think of building a universal programme that can rewrite itself is a task in its own right. It requires logic to understand what to rewrite. It requires logic to estimate the success of the result, i.e. is it worth rewriting. Moreover it doesn’t even consider the task of building the logic and rules for the particular problem you want to exert intelligence on. Its all very well building some software to focus on a particular implementation but what about a universal problem solver i.e. one computing mechanism that can be configure or programmed to solve many different types of problems. Isn’t that the strength of computing in that they are universal computing machines regardless of what they are trying to compute in hand.
What is needed is a framework to standardise our approach and as with all things in the universe when it starts to get hard we turn to mathematics to dumb down our thinking!!! Special Relativity is complex to say the least how dare Einstein simplify it(E=mc2)!

Figure 2.1
![]()
The above equation represents the graph.
Figure 2.1 is a Artificial Network Dependency Graph (ANN)
Typical ANN dependency graph as three types of parameters;-
- The interconnection pattern between different layer of neurones
- The learning process for updating weights of the interconnections
- The activation function that concerts a neurones weighted input to its output activation.
As you can see from the diagram(figure 2.1) we can take an input, apply multiple calculations which in turn can feed into other calculations. However we have one fundamental component that makes the whole framework work and that is the cost function. This can be represented using the following formula;-
![]()
The COST function is an important concept in learning, as it is measure of how far away a particular solution is from an optimal solution to the problem being solved. Learning functions search through space to find a function that has the smallest possible cost. This is achieved through mathematical optimisation.
The above sounds complicated but what it gives us is a framework that we can use to architect a software platform to provide a level of artificial intelligence. As a software engineer we can use these principles to encode rules and ensure those rules learn the success of their application.
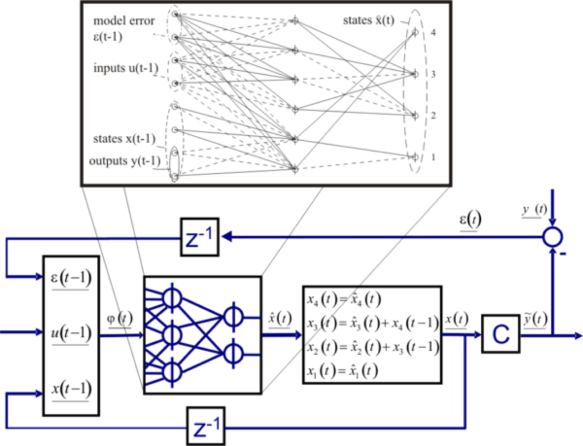
Figure 2.2 – Illustrates the principle of the Cost function and the neural network further.
I believe that the principles of this approach will allow us to achieve convergence of algorithmic, big data and parallel computing with the ability to weight the success. This training principle, if implemented correctly, could overcome the limitation we have with today’s software platforms in achieving intelligence.
However whilst this approach gives us a framework to architect a software programme. As a software developer the prospect of building such a programme is daunting to say the least. As a development community we feed off each other through technology abstraction. We all stand on each others shoulders and incrementally we use a collective knowledge to enhance our innovation. This approach and our current time in history makes A.I. achievable and viable for the average commercial application. However we do need catalysts that could allow us to start using this technology. Fortunately there are developments on the near horizon that could allow us to take an early opportunity.
Emerging usable A.I. Technology
Without loosing site of our zero to A.I approach. We have discussed,so far, the basic mechanics of today’s modern computer. We have then attempted to represent intelligence learning capability and rules definition through neural networks and a COST function. All of which can be represented within a software programme outlined in our earlier example, obviously the scale, size and complexity of this programme would be substantial, however we can see how it can be achieved with time and thought. Now looking ahead, how can we make it easier for ourselves and certainly more commercially viable. My view on this is to follow the lead of the wider software development community through open source. This is ultimately gives us the development scale, intelligence and skills to make A.I. achievable for the average company to get commercial gain from it.

Figure 2.3 – Tensor flow opensource A.I framework
Figure 2.3 illustrate an A.I. framework development by Google as an Opensource project. Tensor flow provides APIs that allow us to build on the concept of a neural network and cost function to exert intelligence from data and informationary input.
Tensor flow history has been controversial, it is a second generation technology with the initial generation coming out of the Google brain project. Fundamentally a very advanced implementation of neural networking, Tensor flow is one of the most advanced and developed frameworks for A.I. available in the public domain under open source. No doubt there are equivalent technologies kept under wraps at Apple, IBM, Oracle, Microsoft, SAP and others, however Tensor flow seems to be the most powerful yet. Certainly it is something we can get a head start with.
This library of algorithms originated from Google’s need to instruct neural networks, to learn and reason similar to how humans do, so that new applications can be derived which are able to assume roles and functions previously reserved only for capable humans; the name TensorFlow itself derives from the operations which such neural networks perform on multidimensional data arrays. These multidimensional arrays are referred to as “tensors” but this concept is not identical to the mathematical concept of tensors, which we will provide more insight on shortly.
The purpose is to train neural networks to detect and decipher patterns and correlations. This framework is available for us now, but what makes it even more appetising is the release last month, May 2016, of a custom built ASIC chip for machine learning and specific tailored for Tensorflow. This is being neatly named the Tensor Processing Unit. Google revealed they’d been running TPUs inside their data centers for more than a year, and have found them to deliver an order of magnitude better-optimized performance per watt for machine learning. Because each chip is inherently small in design i.e. high-volume low precision 8 bit arithmetic processor it put the processor in the realm of Internet of Things computing meaning we can use distributed processing for intelligence allowing us to compute learning close to source, i.e sensors, data or sub systems. This is very exciting for us as it provides machine learning on a chip that could be plugged and played anywhere.
So how does it work?
Understanding Tensorflow first all means we need to understand not only how does a neural network work. We need to understand the concept of Tensors. So what is a Tensor?

Tensors are geometric objects that describe linear relations between geometric vectors, scalars, and other tensors. In terms of a coordinate basis or fixed frame of reference, a tensor can be represented as an organized multidimensional array of numerical values. The order (also degree or rank) of a tensor is the dimensionality of the array needed to represent it, or equivalently, the number of indices needed to label a component of that array.
Tensors are important in physics because they provide a concise mathematical framework for formulating and solving physics problems in areas such as elasticity, fluid mechanics, and general relativity. This for me provides a complex mathematical framework which Google has gone on to use to represent and map learning. These tensors can sum up the total of learning at a particular point in time. By enabling this information to flow through a graph of nodes, with a node being a computation, we can allow the tensor to compute information, which it then can update the tensor to improve the information and therefore knowledge. This concept can be represented and configured in a Dataflow Graph which represents our neural network of data and computations. Tensor flow also makes use of one other concept which are called edges. Edges can be seen has input and outputs from a node which can then enable the tensor to role into another computational node.
What Tensor flow also gives us is useful tools such as Tensor boards which enables us to manage the complexity of the computations that Tensor flow need to be capable of doing such as training massive deep neural networks. These do get complex and the architecture behind them needs to be structured to represent both the machine learning process and the data that will need to be utilised not to mention debugging and optimising programmes that get developed.
Tensor flow is deeply numerical. The first applications of this technology is derived around image recognition as its a natural step when dealing with reams of bitmap data. However the applications are endless. The key to understanding the application capability is by understanding the potential of your data. You need to get in the mindset of how a human being can look at data and make conclusion. What does it mean to me and my business, what decisions can I derive and act on. Once we have this view then how can I plug in technology that can take the data make the decision, store the learning then use the decision within the rest of our technology. This for me is the trickiest part because it simply is not worth the effort to use this technology for today’s simple decisions within, say the average e-commerce website. i.e. this customer bought this and likes these or may want to see this. This problem is simply too simple, AI requires a real problem that only a human could make a decision on. The truth of the matter is that humans reprogramme themselves quickly to perform new tasks. Therefore to do this on a routine basis you would need to rebuild your neural network which again is not efficient. So a real tasks would be the kind of decisions that can be built into a framework or factory of decision making. For example the type of tasks that require humans to process a constant similar stream of information and make informed decisions and learn from those decisions. Conversation, sentiment, image recognition, people recognition, footfall, traffic flows, scheduling, testing, performance analysis. All of which have three types of informations processing;-
- Data gathering
- Data normalisation
- Step by Step Data processing to arrive at a decision
- Compare that decision, can we improve out model
- Can we look at all those micro decisions and abstract not just micro meaning but macro meaning.
- Use of that decision.
The hardest thing for AI is finding the right application for it that makes the effort worthwhile. But when applications can be found and they are perfect for the application of the technology and the benefit to productivity could be exponential.
A.I. Architecture
We’ve hinted over the last few paragraphs the importance of architecture in AI. It’s worth exploring this in a little more detail by introducing the concept of agents. Whilst agents in their own right could just reflect the nodes within our environment enabling us to use the nodes for pure computational purposes. However they could be whole Datagraphs in their own right, each making and learning from their own decisions. This in turn could come together on a macro level to make even bigger decisions. The efficiency of this approach allows us to develop intelligence at every level within our architecture. I think this approach deserves merit and it is something every software architect should start to think about with every component of their enterprise architectures. Can we make each component smart even through we may not have the ultimate application for AI at this point in time? For example, take an average ERP platform, which bits could be enhanced to be smart. Inventory could have some intelligence around stocking and buying patterns. E-Commerce website can have intelligence around demand, finance systems could be intelligent around wider patterns of information. External intelligence could be use to feed demand understand sentiment, feel emotion of consumers, spot a fashion emerging. This approach assumes the role of agents that collectively can work together to feed the machine. The machine then has bigger and bigger options to suggest decisions or even generate ideas. As we develop lines of code we think to ourselves am I being smart in this approach, is it clean, is it efficient? We need to start asking, can I make this little bit smarter? The key is, it’s is all about the sum of all the parts.
One particular application we see for AI in the digital agency world is that of resource planning. Resource planning of valuable people with valuable skills is an art which to me presents the perfect challenge for A.I. Project x needs person of skills y and z to start at time t but person y and z are working on project w for the foreseeable future but client f needs project x starting now and commercial team c need project x to generate revenue by time t – yesterday. Everyone familiar with this problem? Factor in wider environment factors skills y and z are in demand now, but skill m and j are growing rapidly leading to y and z being potentially redundant by time t + 30. Whilst skill m and j are expensive now by a fact of cost x 2. This is exactly the challenge we are looking for. Breaking down the steps of decisions and normalising the intelligence required at a microlevel can allow us to build agents of tensor flows to make decisions at each level based on its wider implications. The problem is, as humans we tend to forget how we arrive at a decision, we use the language “it feels”. It feels is for me wrong, logic is right we therefore need to break down each step in our A.I. architecture and derive micro intelligence that can be used by the sum total to arrive a conclusion and present the rational for the solution. We also need to remember one fact and that is we need to learn, we need to arrive at conclusions to our scenario planning therefore training the system if we arrive at s then that is very bad indeed but at least let the machine know how it got to s and why it is bad. Training like humans isn’t instinct it is learnt behaviour. It doesn’t “feel like” for a reason.
So we are arriving at the end of our journey from zero to A.I. We now should have the confidence that we have the technology capability of building intelligent machines. But appreciate that the problem for A.I. is the problem i.e. the type of application that we can apply A.I. to. We should also appreciate that micro steps are the answer and that applying intelligence in small steps will equal to a sum of all parts approach to A.I. I see the next few years about seeding A.I. Organisation need to have the awareness that the technology is possible and that we need to start sowing some seeds so when the times comes we can reap the rewards of what will be at some point in the future a rapid industry growth. The key as always is both imagination and innovation.
As part of this series of posts, I’ve prepared some presentations that distill this process of thinking further and allow time for each area of this document to be questioned. I’m hoping to present this in person shortly but also video the outcome. The fun part of this process is the fact that we are never too far away from the basics of computing and electronics and working though the journey from zero to A.I. reminds us how remarkable computing and electronics is. To quote Steve Jobs we are truly creating a “bicycle for the mind”.
Next Up : The beginnings of Quantum Computing, how we can continue the evolution of the transistor and the Quantum Leap it can provide our current technology capability.
